3. Automated Data Retrieval - Transaction Listings
Background:
In previous tutorials, we examined the procedure for extracting trial balances from Xero. However, accountants may require more detailed data, such as the individual debits and credits that constitute these balances. Accessing this detailed data allows accountants to deliver in-depth variance analyses and pinpoint causes of balance movements.
In this guide, we will outline a process similar to those previously documented, but with a focus on retrieving transaction listings instead.
Goal
Our current objective is to develop two distinct scripts: one to extract transaction data and another to transform the obtained JSON data into a tabular format.
It is important to note that Xero does not offer a direct API for account transactions. Instead, Xero provides APIs for journal data extraction, which we will utilize as an workaround. This approach will enable access to all entries, whether they are manual journals or system-generated transactions such as those related to invoicing.
For Xero, a significant system limitation to consider is the inability to search transactions by date; instead, journal IDs must be used. Xero assigns these IDs sequentially across all transactions. For instance, if the first transaction following 31 January 2024 is assigned ID 481, then to extract transactions for February 2024, one would need to start filtering from journal ID 482 onwards. Further details will be discussed later in this walkthrough.
Steps
Requirements: Python.
Assuming that script authorization has already been granted - if not, please refer to our trial balance walkthrough - we simply need to adjust the scope variable and the endpoint URL. Additionally, this script will include a section on parameters, which differs from our trial balance example where the date was appended to the end of the URL.
For more detailed information, refer Xero’s API documentation for journals here.
You will need to replace the variables of the following items:
scope = 'offline_access accounting.journals.read'get_url = 'https://api.xero.com/api.xro/2.0/Journals'Within the
XeroRequests()function, you will need to add an additional argumentparamswithinrequests.get(). This is to add additional input parameters so our script can extract transaction items with a journal ID of 481 onwards. ID 481 is used per sighting of the journal listing within Xero - note that all February 2024 entries start from 482.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
import requests
import webbrowser
import base64
client_id = '<INSERT_ID_HERE>'
client_secret = '<INSERT_SECRET_HERE>'
redirect_url = 'https://xero.com/'
scope = 'offline_access accounting.journals.read'
b64_id_secret = base64.b64encode(bytes(client_id + ':' + client_secret, 'utf-8')).decode('utf-8')
def XeroFirstAuth():
# 1. Send a user to authorize your app
auth_url = ('''https://login.xero.com/identity/connect/authorize?''' +
'''response_type=code''' +
'''&client_id=''' + client_id +
'''&redirect_uri=''' + redirect_url +
'''&scope=''' + scope +
'''&state=123''')
webbrowser.open_new(auth_url)
# 2. Users are redirected back to you with a code
auth_res_url = input('What is the response URL? ')
start_number = auth_res_url.find('code=') + len('code=')
end_number = auth_res_url.find('&scope')
auth_code = auth_res_url[start_number:end_number]
print(auth_code)
print('\n')
# 3. Exchange the code
exchange_code_url = 'https://identity.xero.com/connect/token'
response = requests.post(exchange_code_url,
headers = {
'Authorization': 'Basic ' + b64_id_secret
},
data = {
'grant_type': 'authorization_code',
'code': auth_code,
'redirect_uri': redirect_url
})
json_response = response.json()
print(json_response)
print('\n')
# 4. Receive your tokens
return [json_response['access_token'], json_response['refresh_token']]
# 5. Check the full set of tenants you've been authorized to access
def XeroTenants(access_token):
connections_url = 'https://api.xero.com/connections'
response = requests.get(connections_url,
headers={
'Authorization': 'Bearer ' + access_token,
'Content-Type': 'application/json'
})
json_response = response.json()
print(json_response)
for tenants in json_response:
json_dict = tenants
return json_dict['tenantId']
# 6.1 Refreshing access tokens
def XeroRefreshToken(refresh_token):
token_refresh_url = 'https://identity.xero.com/connect/token'
response = requests.post(token_refresh_url,
headers={
'Authorization': 'Basic ' + b64_id_secret,
'Content-Type': 'application/x-www-form-urlencoded'
},
data={
'grant_type': 'refresh_token',
'refresh_token': refresh_token
})
json_response = response.json()
print(json_response)
new_refresh_token = json_response['refresh_token']
rt_file = open('C:/Users/roypa/Downloads/refresh_token.txt', 'w')
rt_file.write(new_refresh_token)
rt_file.close()
return [json_response['access_token'], json_response['refresh_token']]
# 6.2 Call the API
def XeroRequests():
old_refresh_token = open('C:/Users/roypa/Downloads/refresh_token.txt', 'r').read()
new_tokens = XeroRefreshToken(old_refresh_token)
xero_tenant_id = XeroTenants(new_tokens[0])
get_url = 'https://api.xero.com/api.xro/2.0/Journals'
response = requests.get(get_url,
params={
"offset": "481"
},
headers={
'Authorization': 'Bearer ' + new_tokens[0],
'Xero-tenant-id': xero_tenant_id,
'Accept': 'application/json'
})
json_response = response.json()
print(json_response)
xero_output = open('C:/Users/roypa/Downloads/xero_output.json', 'w')
xero_output.write(response.text)
xero_output.close()
# old_tokens = XeroFirstAuth()
# XeroRefreshToken(old_tokens[1])
XeroRequests()
Please be aware that only a maximum of 100 journals can be returned per API call. While the script can be adapted to process multiple batches of journals, this modification is beyond the scope of the current walkthrough.
The data structure of the returned JSON file will require normalization. The logic applied in previous cases cannot be directly used here due to differences in data structures:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
{
"Id": "6a1a7757-2659-4b78-a186-1c329ac53051",
"Status": "OK",
"ProviderName": "myApp",
"DateTimeUTC": "\/Date(1712836739182)\/",
"Journals": [
{
"JournalID": "4fd60e44-2ff6-44f0-ae67-13084e704bdf",
"JournalDate": "\/Date(1707004800000+0000)\/",
"JournalNumber": 482,
"CreatedDateUTC": "\/Date(1710566531267+0000)\/",
"Reference": "",
"SourceID": "e9cb9ecb-58ef-43a8-bd20-69a85338142d",
"SourceType": "ACCPAY",
"JournalLines": [
{
"JournalLineID": "d1741eb1-d6fd-4440-8487-c63168da7ac7",
"AccountID": "66e60a82-99d8-47d1-956b-5baea404acba",
"AccountCode": "820",
"AccountType": "CURRLIAB",
"AccountName": "GST",
"NetAmount": 29.50,
"GrossAmount": 29.50,
"TaxAmount": 0.00,
"TrackingCategories": []
},
{
"JournalLineID": "e3c5d4d0-7818-47d1-a676-c944ddf5cd4f",
"AccountID": "42a56c1a-6141-4bf2-913d-916dc1a35cfd",
"AccountCode": "445",
"AccountType": "EXPENSE",
"AccountName": "Light, Power, Heating",
"NetAmount": 295.00,
"GrossAmount": 324.50,
"TaxAmount": 29.50,
"TaxType": "INPUT",
"TaxName": "GST on Expenses",
"TrackingCategories": []
},
The items of interest above are "JournalNumber", "JournalDate" in Level 2, and all the various items in Level 3.
Therefore, we can use the following script to populate a CSV file:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
import json
import csv
# Load the JSON data
with open('C:/Users/roypa/Downloads/xero_output.json') as f:
data = json.load(f)
# Extract required fields
output_data = []
for journal in data['Journals']:
journal_number = journal['JournalNumber']
journal_date = journal['JournalDate']
for line in journal['JournalLines']:
journal_line = {
"JournalNumber": journal_number,
"JournalDate": journal_date,
"JournalLineID": line["JournalLineID"],
"AccountID": line["AccountID"],
"AccountCode": line["AccountCode"],
"AccountType": line["AccountType"],
"AccountName": line["AccountName"],
"NetAmount": line["NetAmount"],
"GrossAmount": line["GrossAmount"],
"TaxAmount": line["TaxAmount"]
}
output_data.append(journal_line)
# Write to CSV
csv_file = 'C:/Users/roypa/Downloads/xero_output.csv'
fieldnames = ["JournalNumber", "JournalDate", "JournalLineID", "AccountID", "AccountCode", "AccountType", "AccountName", "NetAmount", "GrossAmount", "TaxAmount"]
with open(csv_file, mode='w', newline='') as file:
writer = csv.DictWriter(file, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(output_data)
print("CSV file generated successfully:", csv_file)
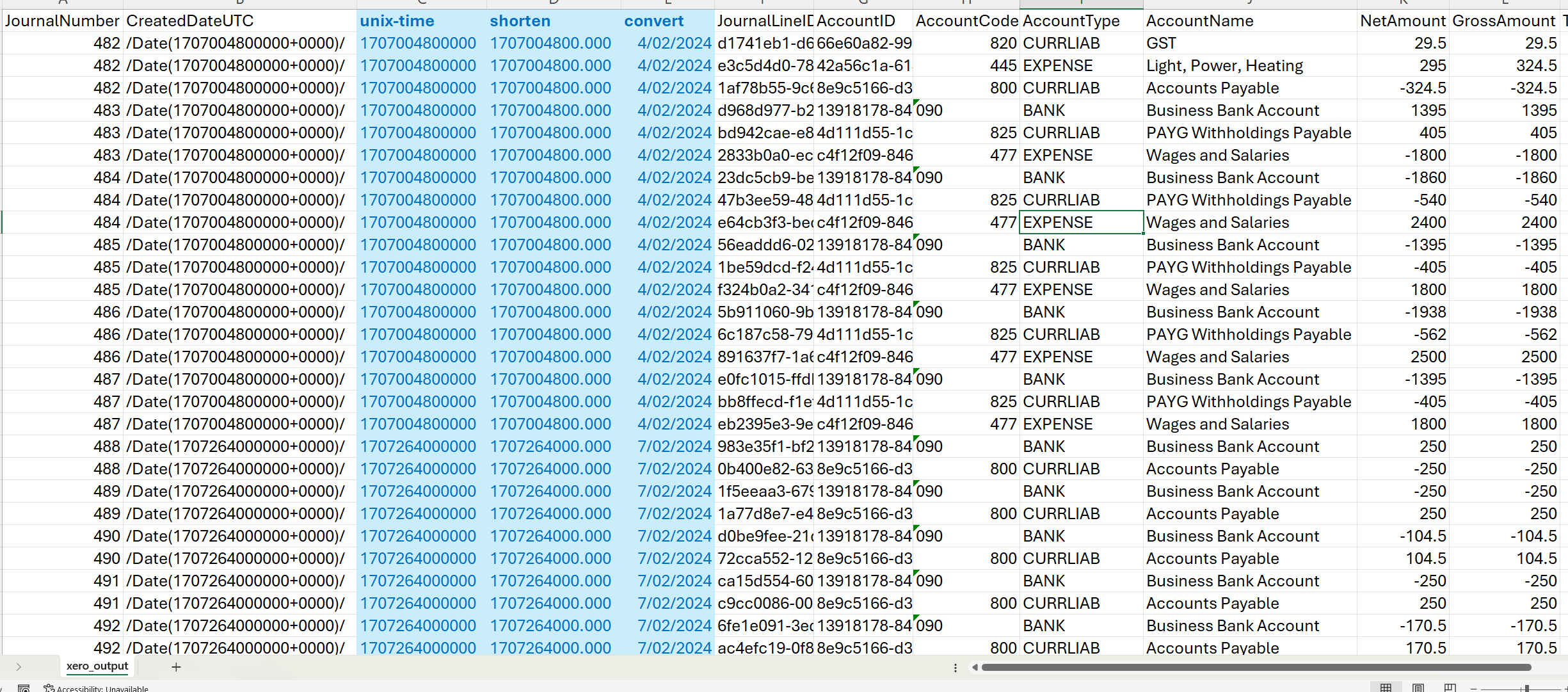
You should now see a newly created CSV file containing our flattened data. Some fields may display repeating values as defined by our script, reflecting a one-to-many relationship (for example, a single balance sheet line item may consist of multiple general ledger accounts).
Note that the date extracted is Unix-time (seconds passed since 1 January 1970). We can apply logic in either our script itself or within Excel to convert them into readable dates.
Conversion formula (Excel):
1
2
3
4
5
Cell A = {unix-time}
Cell B = left({Cell A}, 10) & "." & right({Cell A}, 3)
Cell C = ((({Cell B} / 60) / 60) / 24) + date(1970, 1, 1)
Cell C in the formulas above will give you the desired date - note that you need to set the cell format to “Short Date” or other date formats.
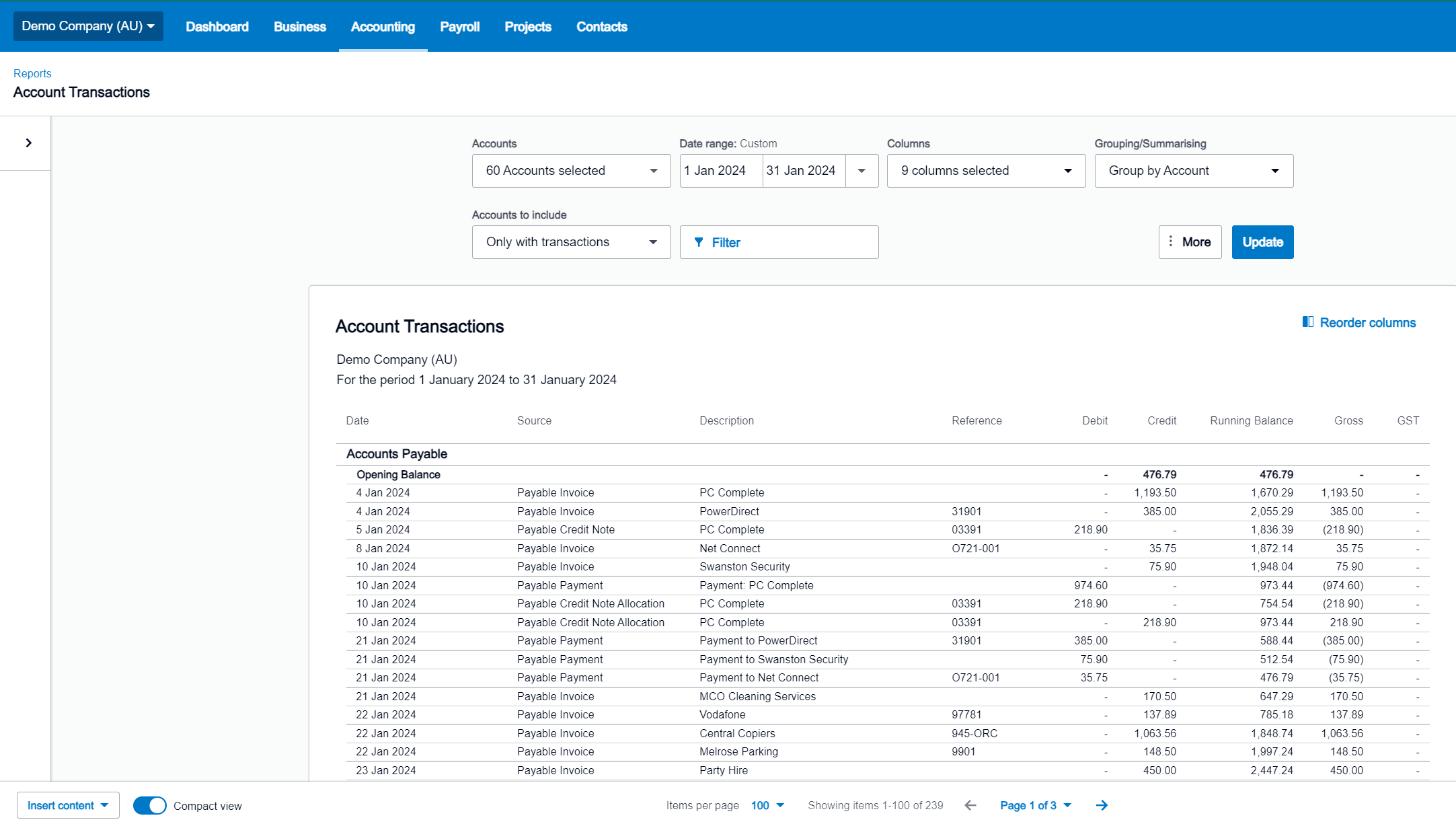
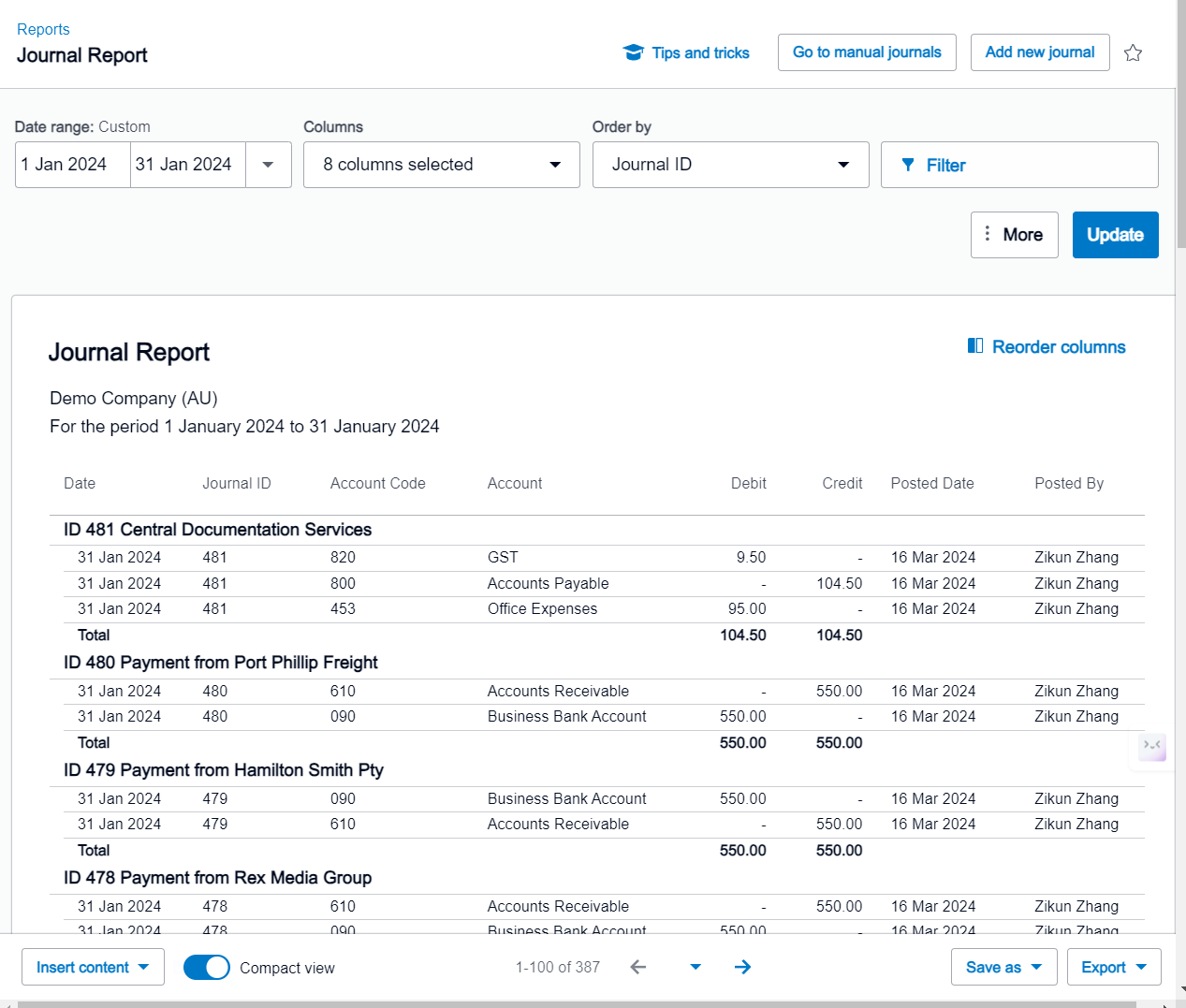
If you cross-reference the extracted data with the data available within Xero’s Account Transactions or Journal Listing functions, you will find that they correspond accurately without any issues.
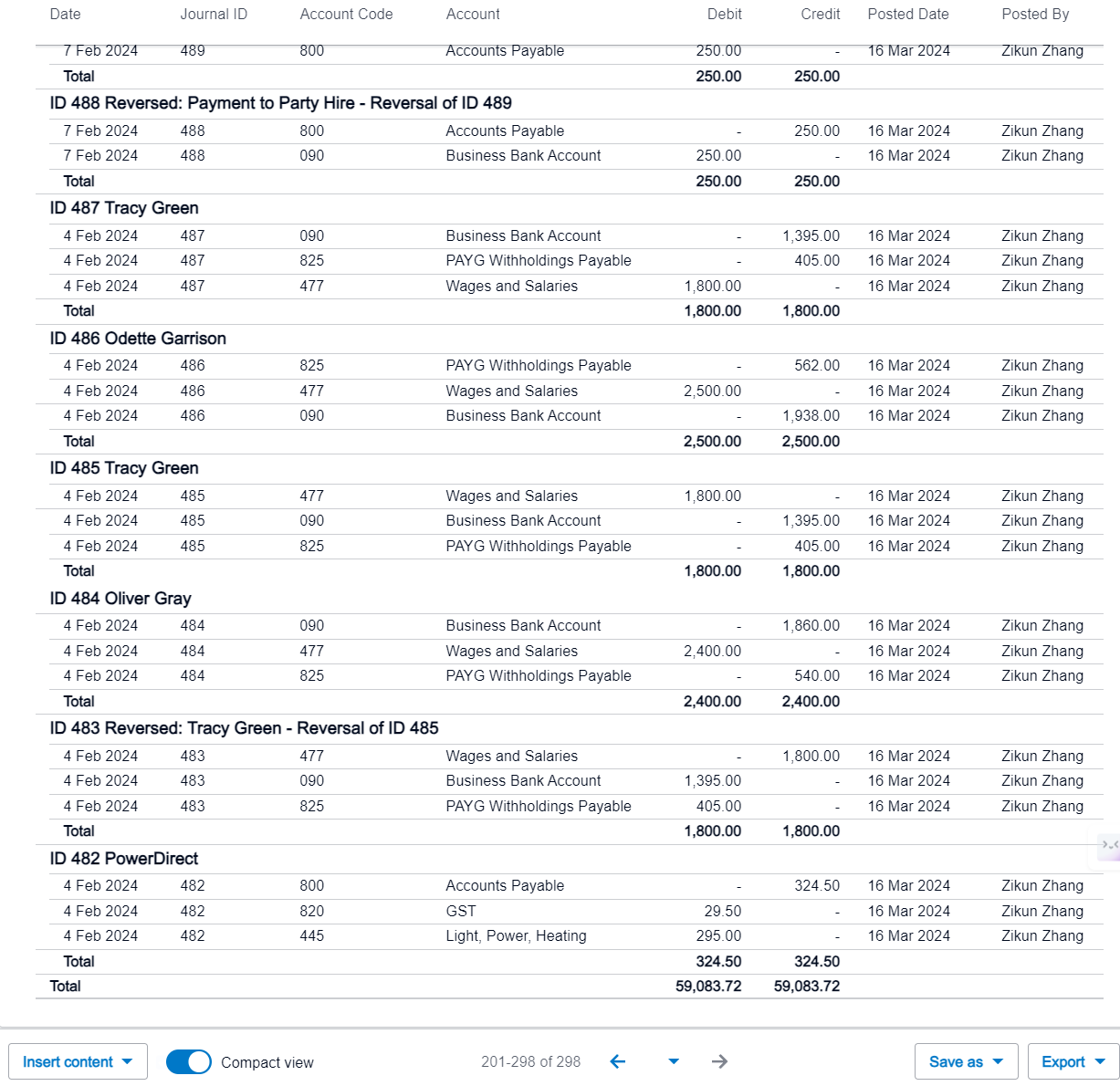 Journal List
Journal List
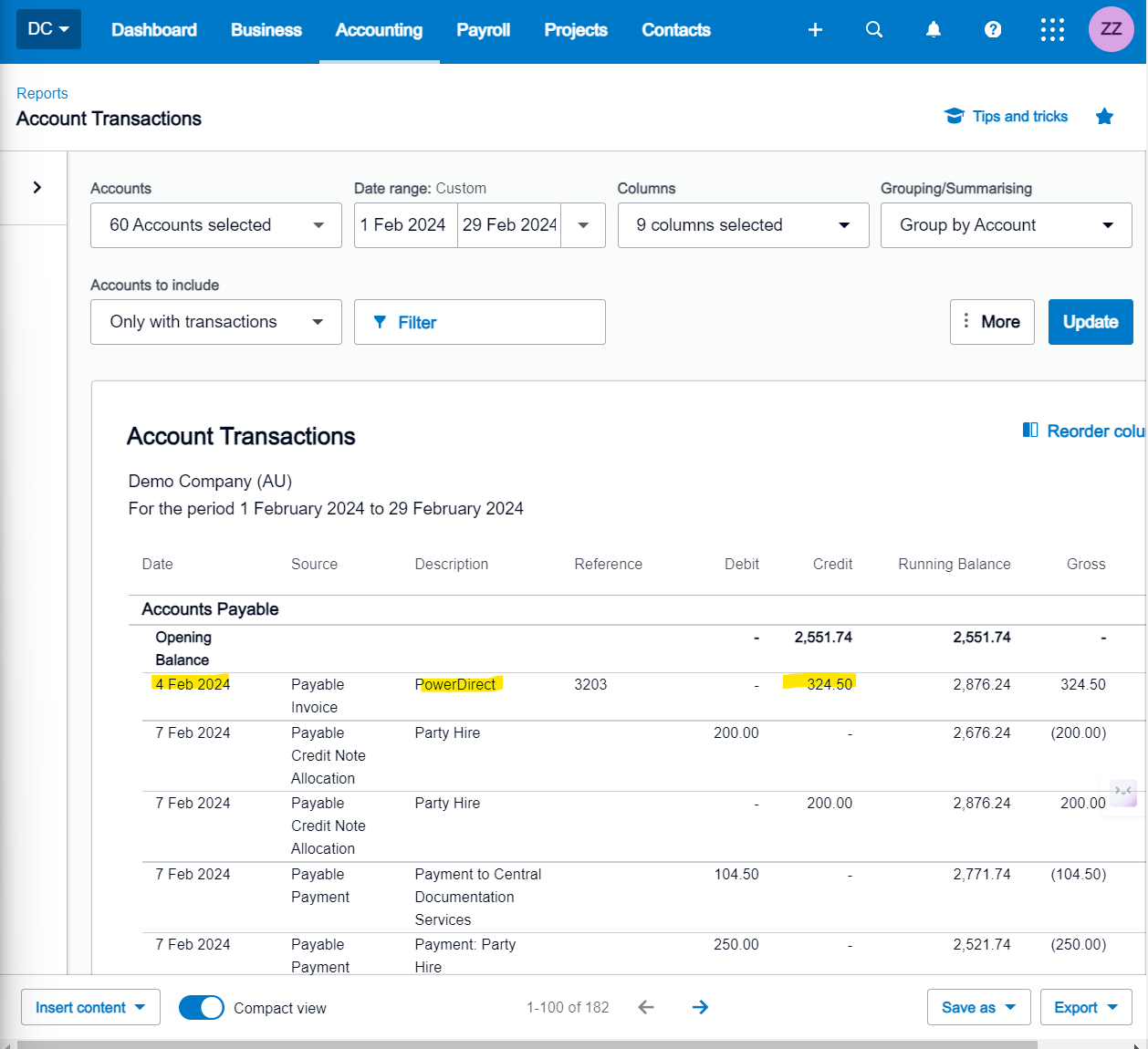 Account Transactions
Account Transactions
As previously mentioned, the drawback is the absence of date input parameters, necessitating manual adjustment of the journal ID number. The end-user is expected to maintain records of the starting and ending journal IDs for each period, especially if they opt to generate reports based on specific time periods.
Outcome
Similar to what we achieved with trial balances, we now have a functional file for transactions.
Until now, our focus has been solely on extracting information from Xero. However, what if we want to automate data uploads to Xero instead? In our next walkthrough, we will delve into a practical example involving the automation of manual journalling, a crucial task for financial accountants.